PollyPDF: Generating Audiobooks from Academic Abstracts
About The Project
Trying to stay up to date with the latest security research is challenging. There are countless security blog posts, and interesting academic papers to keep up with. Realistically you don’t have time to sit down and read everything that looks interesting. Wouldn’t it be great to have your own personal “Audible”-esque service to listen to articles as you did chores around the house? This blog post is about integrating AWS’ Text-to-Speech service, “Polly” to generate audio clips of academic paper abstracts. The idea here is by listening to short audio clips of academic abstracts, you can identify if the content covered is of interest to you before diving into a 30+ page paper. The final workflow looks something like the image below.
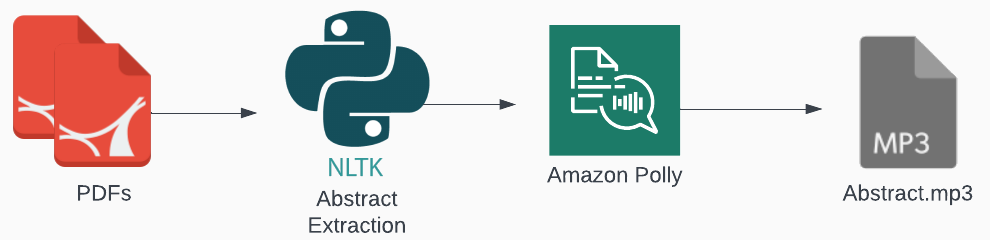
Abstract Text Extraction
A typical academic paper has an abstract section prior to an introductory section on the first page of the publication. Treating this as a “text boundary”, I leveraged PyPDF to extract all text content from the first page of the publication. Next, leveraging NLTK a popular Natural Language Processing (NLP) framework, all text content was tokenized, and the position of introduction section was identified via string data types built in index function. After identifying the position of the “introduction” section all content prior to this position leaves you with the abstract. Or at least it should most of the time… Non-standard paper formats where the word “introduction” does not appear on the first page really throws a wrench into this whole formula. While testing, this didn’t become a real issue so we’ll go with that moving forward.
This entire process can be broken down into the following Python code snippet:
file = open("test.pdf","rb")
pdf_reader = pdf.PdfReader(file)
page1 = pdf_reader.pages[0]
data = page1.extract_text()
# this gives us a list of sentences
sent_text = nltk.sent_tokenize(data.replace("\n"," ").lower())
data = " ".join(sent_text).split(" ")
vdata = "" # "Voice data"
try:
pos = data.index("introduction")
abstract = data[0:pos]
vdata = (" ".join(abstract))
except:
vdata = (" ".join(data))
print(vdata)
With the data extracted, it can now be transformed into an audio clip via AWS’ Polly.
AWS Polly
AWS’ Polly service converts text to audio, which is very simple to understand. The pricing model of AWS Polly is where the real fun begins. Excluding free tier users; you’re charged $4.00 for the first one-million characters submitted against the AWS’ Polly API. However, depending on the voice engine you use you could be charged more! AWS Polly supports four separate voice engines. A brief description taken from the AWS documentation is shown below:
- Standard Engine: A default offering.
- Generative Engine: “offers the most human-like, emotionally engaged, and adaptive conversational voices available for the use via the Amazon Polly console”
- Long-form Engine: “produces human-like, highly expressive, and emotionally adept voices. Long-form voices are designed to captivate listeners’ attention for longer content, such as news articles, training materials, or marketing videos.”
- Neural Engine: produce even higher quality voices than its standard voices.
Each voice engine serves a different purpose depending on the goal of the generated text-to-speech audio clip. For example, the long-form engine is supposed to be more expressive and sound less robotic to the listener and is accessible via the API. Notably the Generative Engine can only be used from the Polly console and not via the API. The standard engine, is far more “robotic” and anyone who’s recieved a “robo call” will feel right at home. There’s also numerous voices associated with each engine further providing customizations for your text-to-audio journey.
The table below is provided by AWS’ pricing breakdown and shows the different in cost depending on the voice engine used. Since this project is only focused on generating audio clips of abstracts, there’s no real concern for cost. Expanding the project scope to bigger PDFs would immediately run into a pretty expensive micro-service. For those worried about AWS costs, I have previously covered building a Discord bot for notifications about AWS billing. This in addition to billing alerts, you can avoid surprise bills.
Standard Neural Long form Generative
Average email message ~3.1k characters ~4 min $0.01 $0.05 $0.31 $0.09
source: https://aws.amazon.com/polly/pricing/
With pricing discussions out of the way, the actual API interaction is next.
The AWS provided APIs make generating the audio file easy.
Copying and pasting the code provided at this page will generate a “hello world” audio clip. Simple replacing the text below with the “vdata”
variable in the previous code snippet, the academic paper’s abstract audio clip will be generated and returned to us via the Python API.
For longer form text generation, voice clips would be stored in S3.
....truncated....
session = Session(profile_name="adminuser")
polly = session.client("polly")
try:
# Request speech synthesis
response = polly.synthesize_speech(Text="Hello world!",OutputFormat="mp3",
VoiceId="Joanna")
...truncated...
The voices provided in this example are fairly robotic.
Its hard to describe, but I encourage you dear reader to experiment with both voice engines and VoiceIds.
I chose the VoiceId of “Brian” and thought it was better than most.
Conclusion
AWS’ Polly service gives you the ability to make your own “Audible” like service with documents of interest. The pricing model, while confusing is not particularly concerning for paragraph-sized data. Anything of substance (entire papers, books, etc..), however, would take me back to the AWS calculator to asses the damage before kicking off a project. The sample code provided is all available in AWS’ documentation and easily tweaked to your unique use case. There is no Github link, just a quick script to run here and there on PDFs which returns an mp3 clip.
Thank you for reading, if you found this useful please consider sharing.