Building A Simple Malware Analysis Pipeline In The Homelab Pt - 2
About The Project
In a previous blog post, I covered how I was obtaining samples, extracting metadata, and querying the results. I’ve moved from testing in Docker containers to stand-alone VMs. Since I have a steady flow of binaries, I need to tag the binaries with something meaningful, so I’m not just aimlessly looking through binary after binary. YARA was the answer for tagging samples. Additional minor improvements were also made in the homelab to prevent any accidental malware execution. Let’s dive in and look at where the pipeline is today!
Improving The Infrastructure - Elasticsearch Cluster of Two
After initial testing with Docker for ease of deployment, I decided to create two virtual machines in the ESXi cluster for more permanent storage. These virtual machines are running Ubuntu server 18.04 with Elasticsearch 7.4.2. Each VM is on a different ESXi server, but the same network. I created the “samples” index with two primary shards and one replica shard. This configuration creates data redundancy across the Elasticsearch cluster. In this scenario, if one node goes down, data should still be recoverable and searchable within the other node.
As data gets brought it, I plan on experimenting with different index configuration to further my understanding of Elasticsearch and what configurations makes sense depending on data size.
Improving The Infrastructure - Malware VLAN++
I made small changesto the malware VLAN since the initial deployment in September. Instead of having a Windows 10 and Windows 7 VM eating up disk space on the ESXi cluster, I moved the Windows 10 box to my laptop and left the Windows 7 in the ESXi cluster. Both machines have the suite of tools made available in the FireEye FLARE PowerShell script. PfSense handles the firewall rules blocking all hosts on this network from communicating with the rest of the home network. The analysis VMs can only be accessed through VCenter, and snapshots exist for each to a known clean state.
The only other notable change is the FreeBSD VM has been replaced with a physical Raspberry Pi 4 B+. The latest edition of the Raspberry Pi 4 comes with a gigabit NIC, onboard wireless (which was disabled), and USB 3.0 ports. A 2TB external hard drive is connected to the Pi to serve as the NFS share for all samples that are rsync’d from the remote download host
Improving The Infrastructure - Preventing Accidental Execution
When moving samples from the download host to the analysis VM, I was incredibly paranoid about accidentally executing a sample. The bastion host that bridges the download host and the analysis VM is a Raspberry Pi 4 B+ running Debian. Since the Pi is an ARM device, I need to be concerned with accidentally executing ARM ELF samples. Currently, ARM make-up 8.9% of the entire malware corpus.
Besides the precautions of ensuring files are read-only, limited user access, and strict firewall rules (both host-based and network-wide via pfSense) in the event of a worst-case scenario), I wrote safteyheader. Safteyheader is a simple Python script that adds four bytes to the header of each executable. If you try to execute an ELF that has a corrupted ELF header, an exec format error is thrown. Safteyheader is executed after binaries have been run through r2elk for metadata extraction and YARA tagging. While the risk of execution is relatively low, it does exist, and any further attempts to mitigate it will help me sleep at night.
Improving The Infrastructure - MQuery Daily Download
To make it easier to obtain the latest samples submitted to Malware API
providers, I added a --daily-download flag to mquery.
This command-line option will grab the samples submitted that day against Hybrid Analysis and Malshare.
Currently, these are the two providers that offer API an endpoint to show recently
submitted samples. If other providers make this endpoint available in the
future, I’ll be sure to add it. Or if there’s one that exists and I’m unaware, pull
requests welcome :).
What is YARA
YARA is “the pattern matching swiss knife for malware researchers.” Researchers develop “rules” that contain value(s) to match against. This value can be a byte pattern, string values, wild card matching, or some combination of all three. YARA rules are then run against a binary to identify if there are any matching values. Additional logic can be applied during searching to require multiple conditions to match. By adding additional logic within the rules, researchers can avoid false positives.
YARA & R2 Integration
![]()
A YARA module exists for the r2 framework. This module is leveraged for r2elk integrations. The r2 YARA module allows users to run specific YARA rules against an open binary. This could be advantageous to CTF players, malware analysts, etc..
Installing R2 YARA Module
To leverage the r2 YARA module, first, initialize the package database via r2pm init.
To see all modules available for r2, execute r2pm search without any
additional parameter. As of November 10th, 2019, there are 160 modules. Several
packages exist for additional processor support, crash dump analysis, or other
API integration. When searching for “YARA”, you’ll see the following data
returned:
r2YARA [syspkg] r2 module for yara. Powerful of r2 functionalities in
YARA [syspkg] yara library and commandline tools from git
YARA-r2 [r2-core] yara plugin for radare2
For clarification, YARA-r2 is a plugin for radare2. r2yara is a module for YARA. The module r2YARA allows YARA rules to leverage r2 functionality in metadata extraction. However, I’m more interested in leveraging YARA within r2, so I need the yara-r2 package.
Executing r2pm -i YARA yara-r2 will result in installing yara and the
plugin for r2.
Verify installation has completed successfully via r2pm -l. The package
can also be verified by launching r2 and executing YARA.
Executing YARA Rules within R2
For initial testing, I created a simple YARA rule that matches on the “ELF” (0x7f\0x45\0x4c\0x46)
header. The incredibly simple example YARA rule can be found below.
rule found_elf
{
meta:
author = "Arch Cloud Labs"
date = "2019/11/5"
description = "Detects ELF header"
category = "Example"
strings:
$elf = {7f 45 4c 46}
condition:
$elf
}
The module can be added within the r2 shell via YARA add /path/to/yara/rules.
Or rules can be placed within the ~/.local/share/radare2/plugins/rules-YARA3 directory.
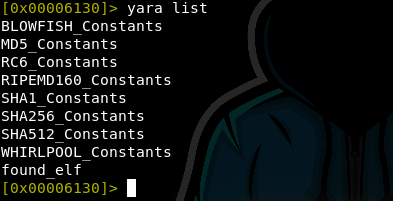
The command YARA list will list all currently loaded rules. The image
below shows some other rules that are already loaded.
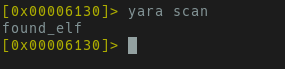
Open any ELF binary and execute YARA scan within the r2 shell
to run all loaded YARA rules against the binary. If a match occurs, the matching
rule name will be printed to the screen.
The YARA-r2 bindings may also be fruitful for some CTF challenges. Immediately searching for the word “flag” that has been XOR’d or a series of bytes indicative to a flag format could result in solving some simple challenges.
YARA Python Module
It’s a bit redundant to launch YARA through r2pipe. Instead, I will use the standard
Python bindings for YARA (yara-python). The yara Python module
is incredibly straight forward to use. After giving the object a set of rules,
you provide a binary (variable fname below) to execute the match
function against.
The snippet below shows how easy it is to integrate YARA pattern matching into a utility.
yaraObj = yara.compile(self.yara_rules) # Read in YARArules
matches = YARAObj.match(fname) # Match YARA rule against binary
yara_matches = []
for match in matches:
yara_matches.append(match.rule) # For each match append it to a list.
print(yara_matches) # Print list of matches.
After integrating YARA rules into r2elk and leveraging the YARA rules provided
by Virus Total, each binary gets a plethora
of YARA rules executed against it. If a rule matches, the yara_rules field is populated
with said matching rule. The image below is the result of the njrat YARA rule.
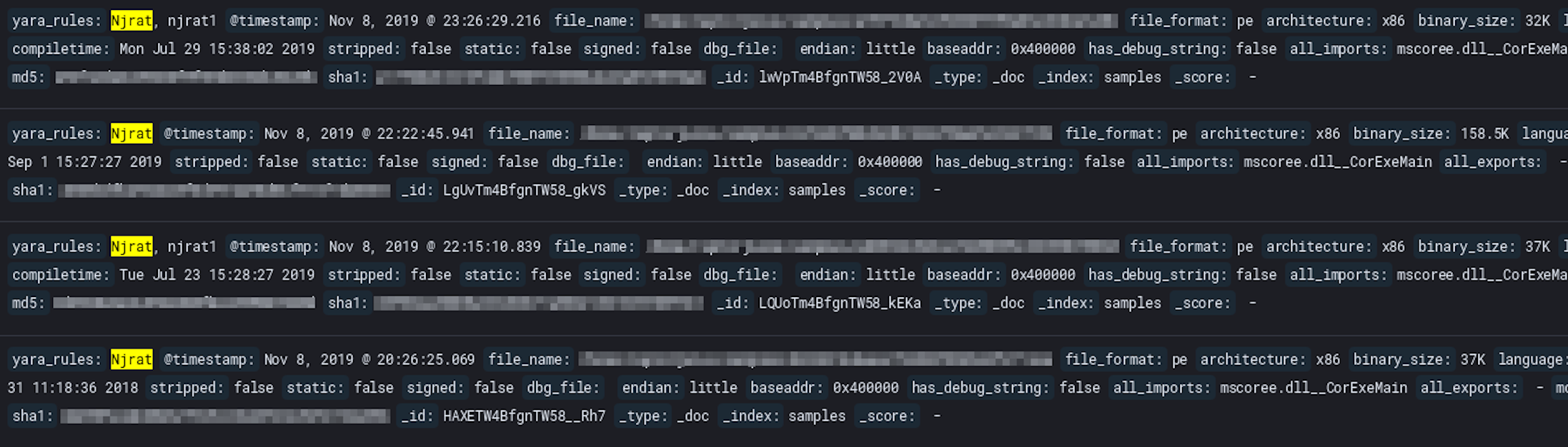
Now that samples are tagged with YARA rules, I can easily search the corpus for an interesting sample (based on YARA rules) to take a deeper look at said sample. I also can identify recently compiled versions of a particular sample family and try to identify if any modifications have been made between samples. At this point, the worlds my oyster and I can finally dive into some of the samples.
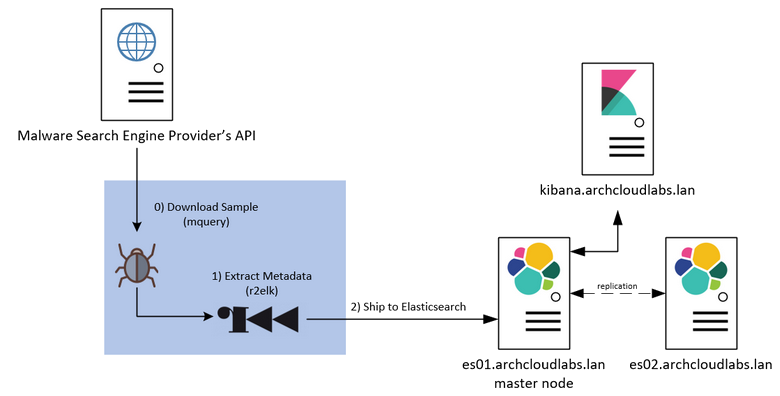
Recapping Data Flow
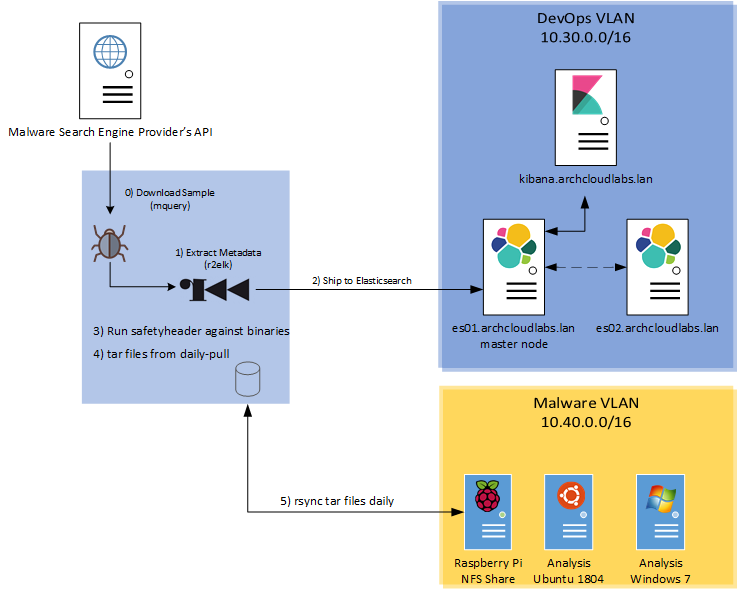
To recap, the current data flow for the malware analysis pipeline works as follows:
- Download samples from providers via mquery.
- Run r2elk to extract metadata and run YARA rules against samples.
- Ship results of r2elk to Elasticsearch.
- Run safteyheader against binaries to prep for shipping.
- Tar up daily downloads for storage.
- Sync to isolated Raspberry Pi network share.
The network diagram below also encapsulates the flow.
Next Steps
With the data coming in daily and infrastructure in place to support analysis, I can finally dive into analysis. If you have any tips/suggestions on how to make the pipeline better, @me on Twitter! I hope you found the content entertaining and informative. Thank you for taking the time to read this.