Scaling Dumb Fuzzing with Kubernetes
About The Project
The e-zine tmp.out focuses on ELF/Linux related research in a style of Phrack. After reading an article on fuzzing radare2 for 0days in 30 lines of code, I thought it would be a fun weekend project to extend this research, and port their code to a container and deploy it in a Kubernetes cluster. To take it one step further, building fresh releases of the radare2 project’s master branch, and integrating it into a CI/CD pipeline which then deployed container builds to a Kuberentes cluster seemed like an excellent way to really go overboard and just eat away my entire weekend. The end result ended up looking something like the following diagram.
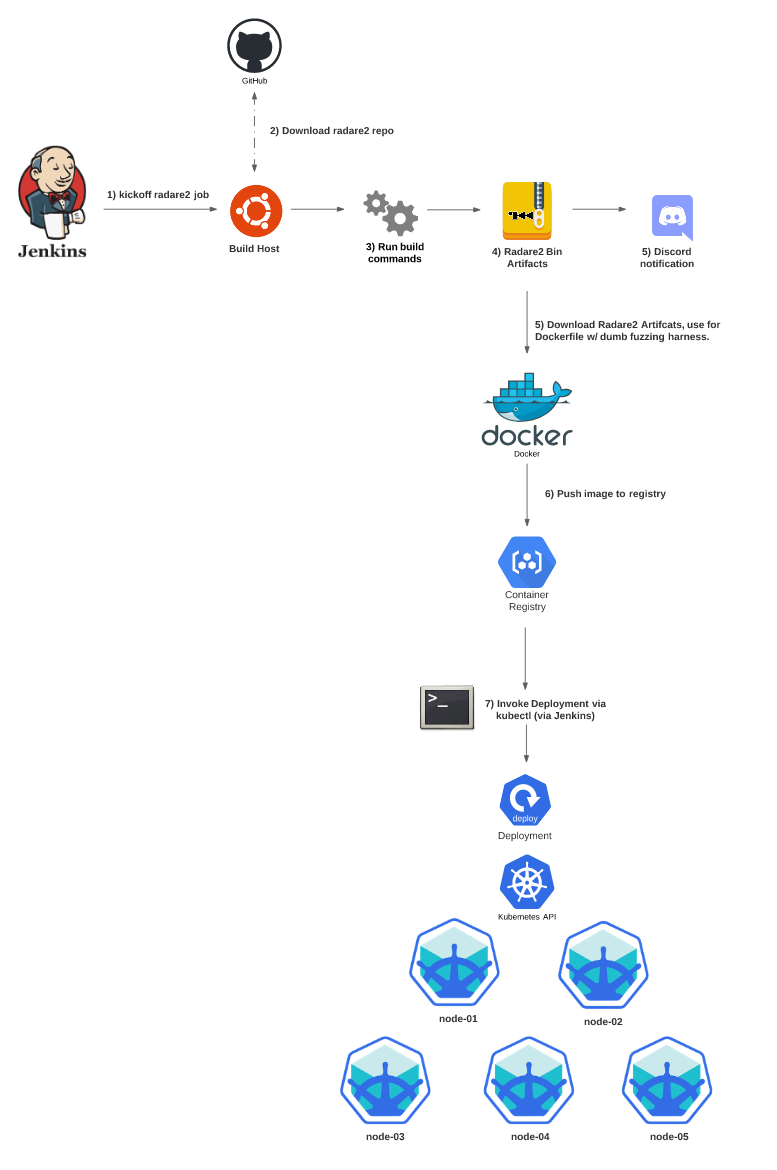
This blog will focus on how to speed up dumb fuzzing and discuss some of the issues I ran into while scaling a dumb fuzzing harness with Kubernetes.
The Most Ineffective Way to Fuzz
So let’s talk about the elephant in the room, why would we dumb fuzz radare2? Well what is dumb fuzzing? In a nutshell, fuzzing at its core is throwing malformed input at a given target binary (in this case radare2) to hopefully elicit a crash. At that point we’ll inspect the crash and see if this could be used for something beyond a local DoS.
Now, the “dumb” part about this malformed input is we’re just manipulating random bytes of a binary from our binary corpus’ arbitrarily and then calling radare2 on the binary to process and analyze it. This is accomplished in the following lines of code from the previously linked tmp.out article:
def mutate(data):
mutable_bytes = bytearray(data)
for a in range(30):
r = random.randint(0, len(mutable_bytes)-1)
mutable_bytes[r] = random.randint(0,254)
Why is this an ineffective fuzzing technique? Well, the knowledge of the underlying file formats (PEs/ElFs/etc…) is widely available, and we could focus on manipulating the respective headers of these binaries in a more intelligent way to target specific portions of the target binary’s code. For example, perhaps we’re concerned with the latest changes to the ELF import parsing section of a given binary. In this case we could build our mutation around the .dynsym/.dynamic/etc… sections.
The nice thing about dumb fuzzing some random bytes is how easy it is to setup. As the original authors have detailed in their article, the workflow here is to just:
- Read in a binary from a binary corpus
- Randomly change some bytes of the binary.
- Have Radare2 attempt to analyze the binary with a given timeout value.
If the timeout is exceeded or a crash occurs a status code of non-zero is generated indicating that “something interesting happened”, let’s save off this modified binary for manual analysis later.
To answer the question posed at the start of this article “why dumb fuzz at all if it’s so ineffective?”, the beauty is in the simplicity. If you have spare Raspberry Pis or any old computer sitting around, why not just passively allow the CPU to go “brrr” on some data and see if any interesting crashes get generated? It’s an nice way to dip your toe into the water of fuzzing, and then venture down some of the more advanced topics that people like Gamozo Labs, Fuzzing Labs, and H0mbre cover in their respective platforms.
Fuzzing The Latest and Greatest Versions of Radare2
Now I know what you’re thinking “Why use Jenkins when $NEW_CI_TOOL exists?”. Jenkin is like a 1985 F150. I know what I’m getting into when I get behind the wheel. At the end of the day all of these tools are glorified remote code execution utilities, and Jenkins is provides the flexibility to do weird things. Simply put I use Jenkins because I like Jenkins.
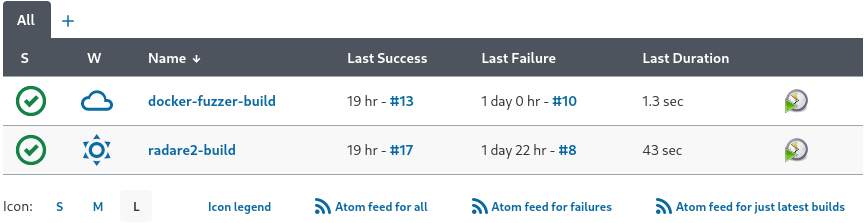
Radare2 is a pretty quick moving platform and has an active community on Github. To ensure I was dumb fuzzing the latest and greatest builds, I created a Jenkins job to periodically pull and build radare2 bins from the master branch, and then publish the artifacts. Once the artifacts are published a separate job was triggered to fetch the artifacts from the Jenkins server, and then build a new Docker container which has the dumb fuzzer harness from the original tmp.out article as well as the corpus of binaries. Jenkins’ default status page shows both builds successfully ran 19 hours ago and both had some issues a couple days ago while I was troubleshooting.
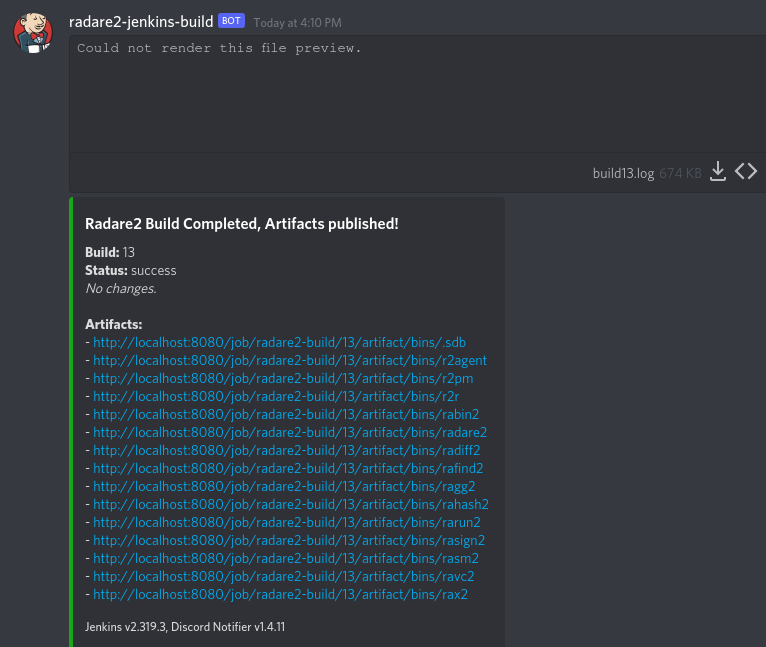
Finally, a notification is sent via a webhook to a Discord server informing me that the radare2 build was successful and the images are available. I find that webhooks + Discord are the easiest way to introduce notifications into a side project, but if you have alerting setup for something else in your homelab you could probably integrate it there as well.
Minikube - Prototype K8s Projects Faster
The fuzzing harness itself is a simple Python application. When discussing scaling fuzzing or any application there’s a lot of things to consider when considering the underlying type of workload. Simpling adding more CPU is rarely a good idea as it’s not solving the underlying bottle necks that likely exist in an application. However, this isn’t a production workload nor is it an production app so let’s take a look at possibly the worst* way to scale a fuzzing application by making several instances run on a handful of nodes. This is where Kubernetes comes into play.
There are several different “developer” focused K8s distributions. I’m a fan of minikube for local development because of the flexibility of the underlying runtime, and virtualization driver. By default it uses Docker for standing up the control plane, but you can opt for KVM and spin up dedicated virtual machines for your workloads to run on. This also allows you to play around with scheduling and shutting off varying nodes to see if pods get re-distributed as you’d expected. It’s also easy to add and remove nodes via minikube node add or minikube node delete. For scaling dumb fuzzing to incredible heights I deployed five nodes on my KVM host.

The deployment manifest leverages an underlying volume mount on the KVM host into the container’s cdir (crash dir) so that any successful crashes are saved off to the underlying hosts storage. This was the simpliest way to achieve persistent storage of crashes within Minikube from what I can tell.
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: dumb-fuzzer
name: dumb-fuzzer
spec:
replicas: 20
selector:
matchLabels:
app: dumb-fuzzer
template:
metadata:
labels:
app: dumb-fuzzer
spec:
containers:
- image: 192.168.39.136:5000/fuzzer
name: fuzzer
volumeMounts:
- mountPath: /opt/fuzzer/cdir
name: fuzzer-vol
volumes:
- name: fuzzer-vol
hostPath:
path: /opt/fuzzer/
type: DirectoryOrCreate
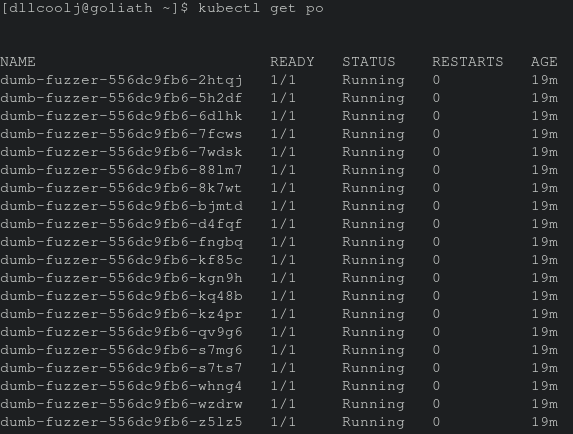
Minikube has a Docker registry add-on that all the nodes can use if you specify during cluster launch that a insecure registry will be listening on a given address. minikube start --insecure-registry="192.168.0.0/16" (set the CIDR range to your virtual network). This makes it super easy to have an all-in-one development environment for building, pushing, and deploying container workloads on your dev machine. The final Jenkins build after the newly build docker fuzzing harness image has been built executes rollout restart to obtain the new Docker image in the Kubernetes deployment. The image below shows the pods running and churning away on binaries.
Interesting and Not So Interesting Crashes
After letting the dumb fuzzers go brrr on the corpus of binaries for a couple hours numerous crashes were generated. However, most were actually self-inflected. At first I attempted to deploy 100 pods, and what occurred was resource exhaustion on the underlying nodes which resulted in processes dying, and the harness saving off the binaries as crashes when in reality it just ran out of memory. So yes a crash did happen, but it was mostly self imposed. After adjusting the workload to a more reasonable 30 pods, more files were generated but again, not all of them resulted in crashes. One key component of the fuzzing harness is the timeout value with subprocess.run If the binary just hangs the process for a prolonged period of time, it’ll be considered a crash and saved off to the crash dir (cdir). So now comes the manual part of inspecting these files to see if it was indeed a crash or if it casued radare2 to hang.
try:
p = subprocess.run(['r2','-qq', '-AA','wdir/tmp'], stdin=None, timeout=10)
except:
return

At first I assumed the “hanging” was due to file size, but upon a closer look it was a 2.5k file resulted in a >5 minute wait time until Radare2 just kills itself. This is interesting and definitely worth taking a deeper look at as one could think of this as an anti-analysis technique or perhaps the tip of the iceberg on something that if manipulated appropriately could crash the target binary.
Finally, when verifying the generated crashes from the Kubernetes cluster I did come across a binary that in fact resulted in an immediate crash. Success! A real crash from the dumb fuzzing adventure. Now it’s time to investigate!

Analyzing The Crash
Now that we have a successful crash, we have to identify the underlying issue. This particular file is a MS-DOS executable, NE (unknown OS 0). The format is important to know as this is going to correlate to what C file we inspect in the radare2 project. Doing a quick diff of the first 50 lines of hex output of both the original file from the corpus and we can see a nice image of what bytes were manipulated by our fuzzing harness. Remember the harness just arbitrarily manipulates bytes, there’s no rhyme or reason why one or another was chosen.
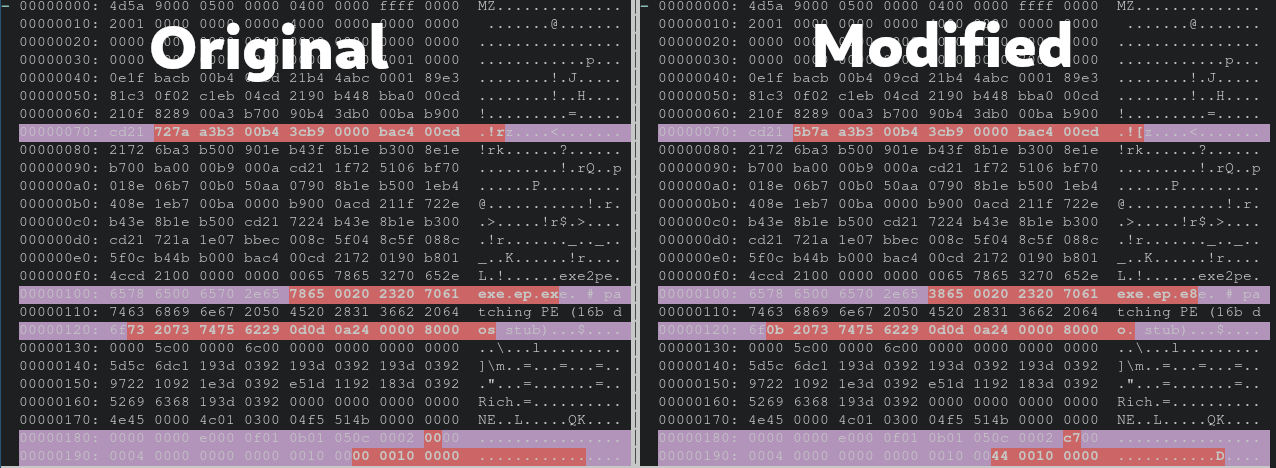
Now let’s load this into gdb and look at the stack trace.
gdb> set args -qq -AA crash_<UNIQUE_ID>
gdb> r
This results in successfully replicating the crash and now we can take a look at the backtrace.
gdb> bt
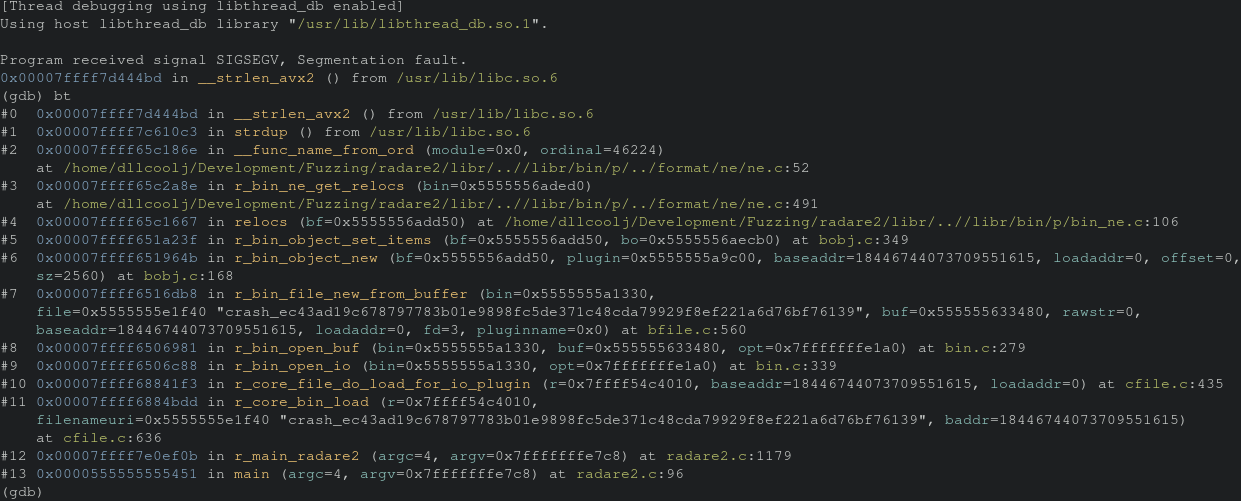
Inspecting frame 2 we see that’s the last piece of radare2 code before we go to libc. So let’s inspect that
gdb> b ne.c:52
We hit the previously breakout point twice before crashing. Now when hitting the breakpoint again, we can single step through until the code that is causing the issue.
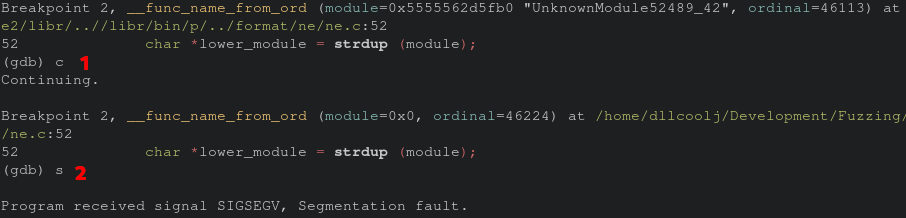
Sure enough it appears to be the strdup function call within __func_name_from_ord. According to the man page this function call returns a pointer to a new string based on teh string specified as a parameter. Re-executing the program through gdb and inspecting the “module” parameter the first time we see there is in fact data at the module.
Something funny to note, in the original research article in tmp.0ut, strdup was also the source of the crash which resulted in the authors geting two CVEs (CVE-2020-16269, CVE-2020-17487).
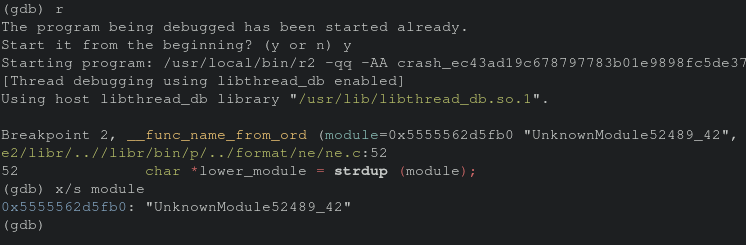
Looking at the difference of the values of the module parameter we can see issues accessing memory when we hit the second breakpoint thus the crash.
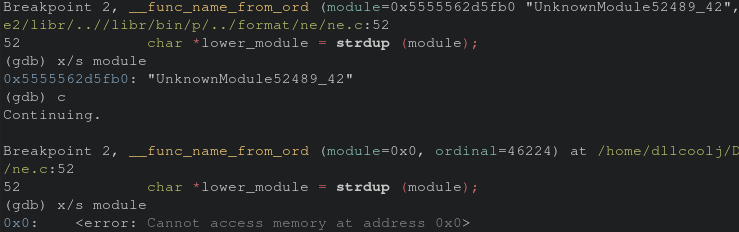
Prior to executing the strdup, a check against module should be performed to ensure it’s a valid string. To verify my understanding of this bug, I creategd a quick scratch program to recreate the issue on a smaller scale.
int main() {
char *tmp = "hello world";
char *tmp2 = NULL;
char *test=strdup(tmp);
printf("%s\n", test);
char *test2 =strdup(tmp2);
printf("%s\n", test2);
return 0;
}
While “hello world”, will be printed, tmp2 will result in a crash as the underlying value. Final verification via stepping through the app in gdb shows the same issue with strdup and not being able to access memory.
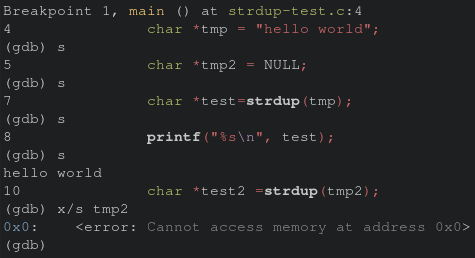
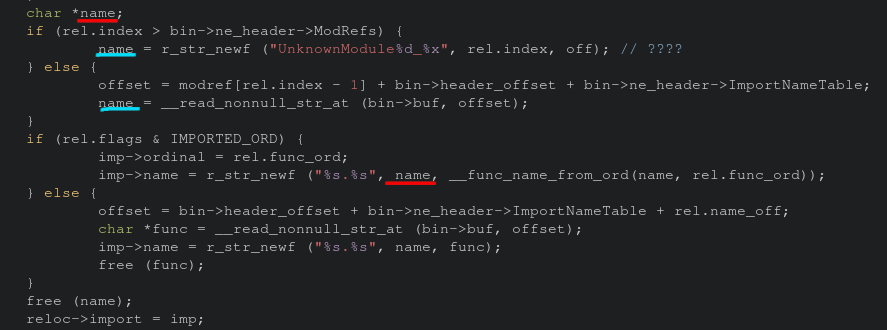
Finally, we have a good image of how the crash is happening, but what about why? Let’s take a step back and see how data is getting passed to the vulnerable function.
How Data is Passed to The Vulnerable Function
The vulnerable function __func_name_from_ord is only called in one file, ne.c specifically on line 488. This function call is within a stub that iterates over the program’s segments. There are conditions where name will not be set to any value, thus there’s no string for strdup to duplicate. This is shown in the code snippet below. Luckily this is an easy fix, and a PR is inbound!
Conclusion
From Kuberentes to GDB this project spanned the gammit on things I like to mess with in my free time. While dumb fuzzing isn’t the most efficient method for vulnerability discovery, it does provide a use for your CPU during “off hours”. Consider how some people mine Cryptocurrency when they’re not at their computer. Maybe they get some coins, maybe they don’t but either way their CPU won’t sit idly. I think that’s the best way to look at it. You also have to start somewhere, and the barrier to entry to low. Thank you for taking time to read this, reach out to me on Twitter if I got something wrong :) (@DLL_Cool_J).
Below, are some additional thoughts I had of issues with the current Minikube setup I couldn’t wedge into the blog.
-
Issue: Large Docker Image Having a dedicated corpus of test binaries that are mounted onto the nodes via a NFS share and then mounted into the underlying container would greatly reduce the Dockerimage size. I was simply “running with scissors” and didn’t take the time to do it this weekend.
-
Issue: Copying off crashes Minikube creates a dedicated ssh key pair per-kvm node that’s deployed. This can be obtained via
minikbue ssh-key -n NODE_NAME. However, a more “Kubernetes way” would be to have a side-car application for pushing the crashes to specific central location. Perhaps to S3 or even just have a NFS share as a separate mount within the container.