Covid-19 Domain Analysis
About The Project
Over the past two weeks, I have been analyzing registered domain names correlated to the current pandemic as a side project. This was all inspired by @jeremiahg’s tweet about the ever-growing number of registered domains related to “covid-19”.
During times of crisis, malicious actors act to profit on those in fear or those showing compassion for their fellow humans. One such avenue of profit phishing. There is no shortage of historical data relating to scams during times of crisis([0][1][2]) to capitalize on fear (click this to be safe) and sympathy (donate here for a good cause). It is well known malicious actors purchase believable domain names, and create a site to accept donations, or masquerade as other legitimate sites to harvest credentials, credit card numbers and other forms of data for financial gain.
From my very limited dataset, I was able to take a small peek into what is currently being done with regards to phishing domains by malicious actors. Wherever possible I have outlined how data was obtained so other researchers with more resources may recreate and expand upon these findings.
Obtaining The Dataset
Several providers exist that offer historical and current domain registration data([0][1]). As a home lab enthusiast, I unfortunately can’t subscribe to all of the services due to the financial strain. However, whoisds.com offers free text files with recently registered domains within the past four days. The data comes in simple text files with newlines separating each domain name. Thanks to this free service I was able to dive into corona related data and do some basic analysis.
The data set I downloaded contains domains registered from the dates of March 12th through March 23rd.
After combining the text files, I performed the following regex to extract potential corona related domains.
grep -Pe "(corona|covid|covid19|virusc|hoax|pandemic|who|symptoms|illness|quarantine)" domains.txt > parsed_domains.txt
While some false positives would undoubtedly be caught with this regex, with 16,194 domains it was certainly a starting point. I’d like to note that after reviewing additional datasets released by DomainTools, this regex was not nearly broad enough to capture all possible corona related domains. For example, I ran across several domains that were substituting “i” for “1” and “o” for “0”. This data analysis performed below does not include the DomainTool’s dataset.
Analyzing whois Data
By leveraging whoapi’s service for JSON based whois lookups, it was trivial to quickly iterate through the list of “parsed_domains.txt” and gather whois information for further analysis.
At this point, you might be thinking “paying for whois data? Why don’t you just perform whois on $DOMAIN?”.
During the project, I discovered you can become a rate limited by whois servers.
It was far easier to pay for the service and focus on the data, rather than spin up cloud compute instances and leverage different IPs for whois queries.
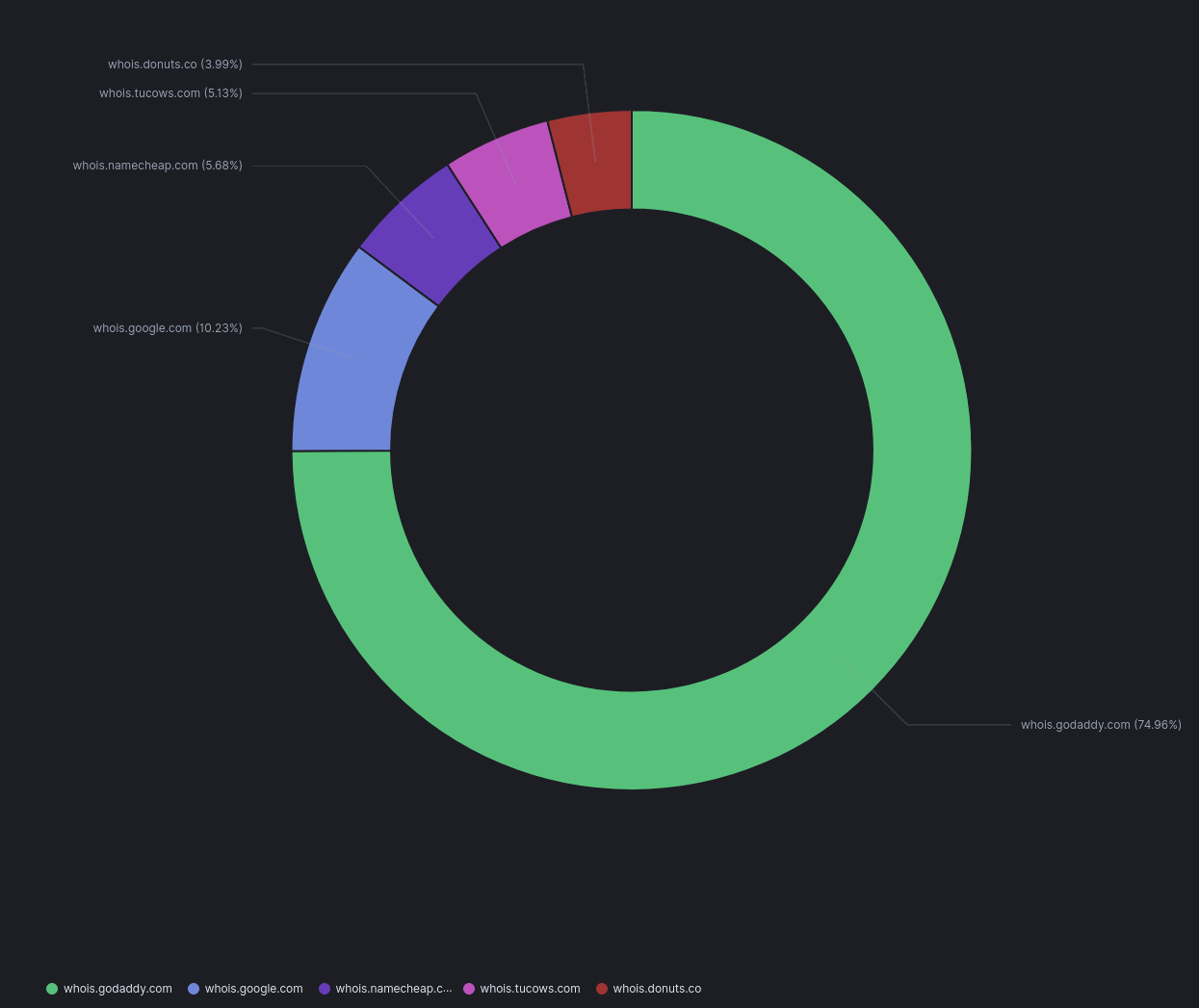
Initial trends show GoDaddy as being the largest registrar for domains within my dataset.
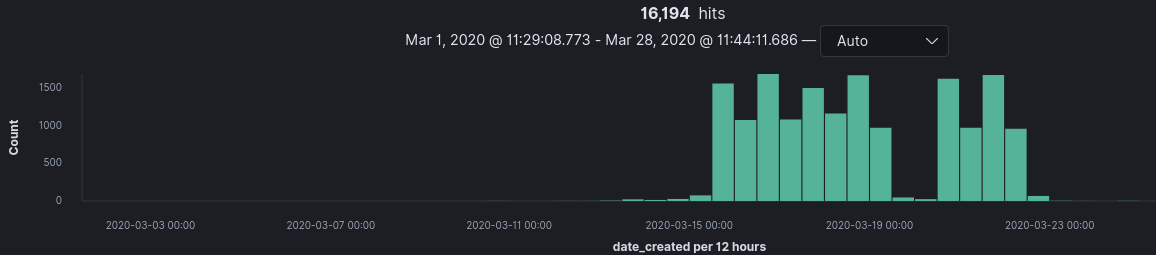
A significant portion of domains were registered on March 15th and March 18th. On March 14th world leaders announced new websites being published to assist in spreading corona information. Correlation doesn’t mean causation, but it’s an interesting uptick in domain registrations regardless.
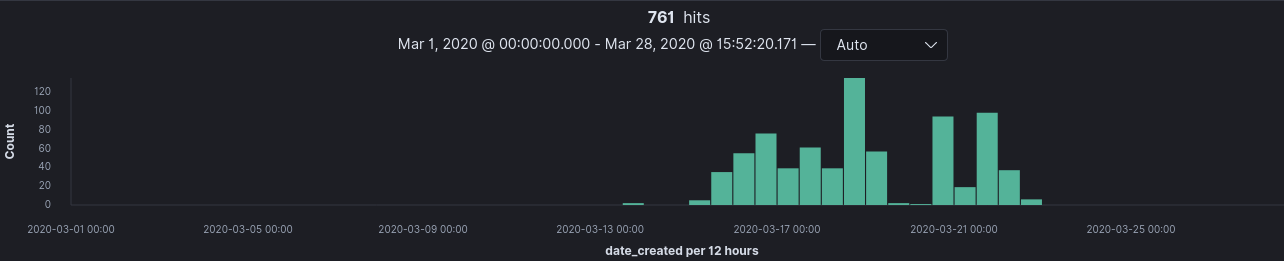
To breakdown the domains even further, I created separate KQL queries in Kibana to return domains with financial and medical and terms in their names. These queries and their results break down can be seen below.
Financial Related Domain Breakdown
domain_name : (*bank* or *finance* or *money* or *cash* or *reward* or *refund* or *claim* or *fin* or *fund* or *relief* or *business* or *credit* or *loan* or *pay* or *payday*)
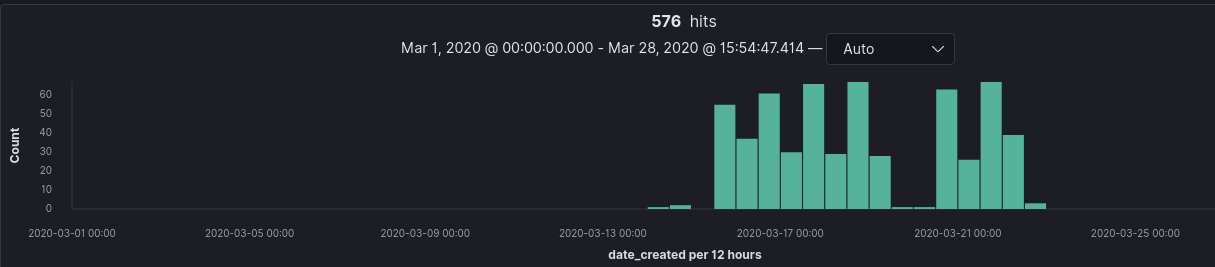
Healthcare Related Domain Breakdown
domain_name : (*medicine* or *cure* or *aid* or *fix* or *health* or *treatment* or *tests* or *wellness* or *care* or *wellbeing* or *protection*)
Taking Screenshots
After gathering whois data, I wanted an image of all the sites to get a brief understanding of what they were offering. By leveraging the webscreenshot utility and a bit of Python logic, iterating over all domains and taking screenshots was trivial. It also revealed that approximately 2,242 domains had errors while iterating through the dataset, resulting in 13,952 images. This is not to say server 500 errors were returned (this is documented later), but rather domains failed to resolve anything at all or an issue occurred during the image processing.
The screenshot data revealed domains were mostly parked. Parked domains are simply registered domains without any service being hosted there. Below is an example of a GoDaddy parked domain.
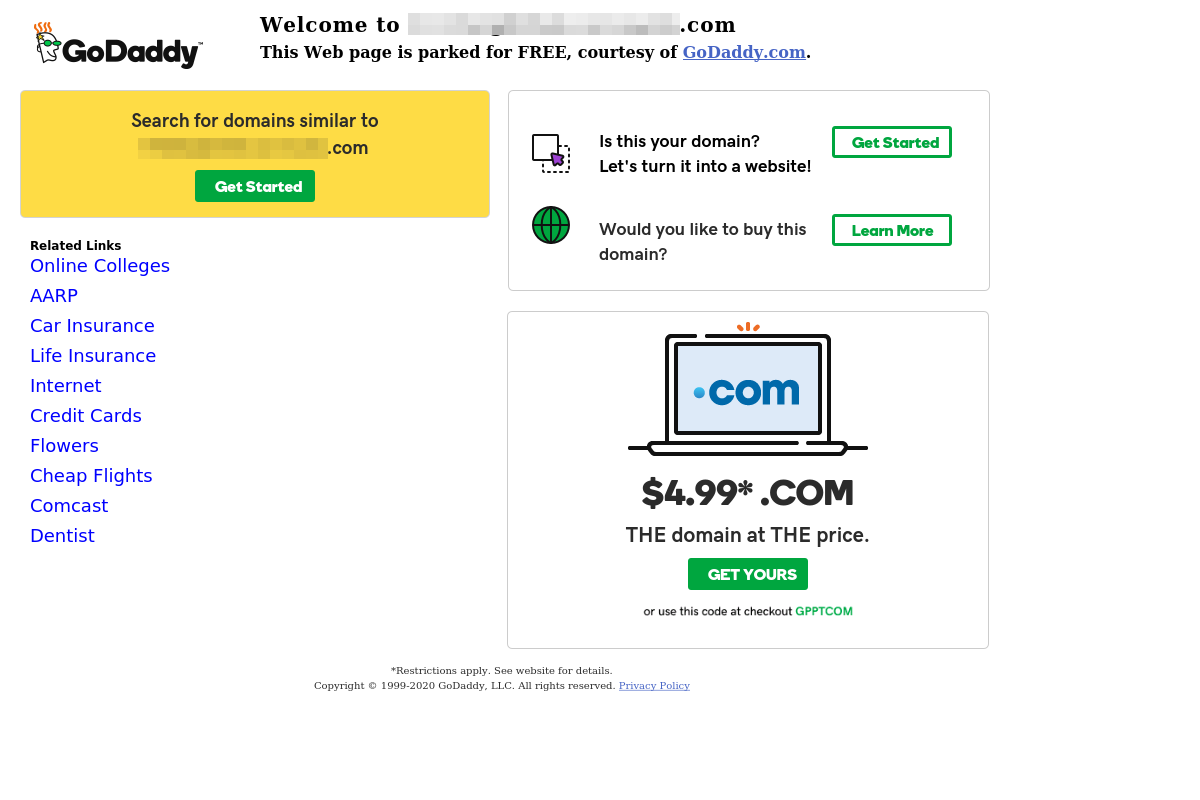
There are numerous reasons an individual may choose to do this. Based on this dataset, a fair amount of these sites were purchased just to resell. Below is a subset of my findings.


OCR Overview
After going through 9k+ screenshots by hand and understanding what there was within this dataset, I was curious about how to automate extracting text data for analysis. This is where Optical Character Recognition (OCR) came into play. OCR enables you to extract text values from images. Given that a vast amount of screenshots held “parked” domain images from various hosting providers, I wanted to extract all the text and see how many were parked and by which registrars. Additionally, all other data would be extracted to aid in further analysis.
OCR Applied - Parked Domains Breakdown
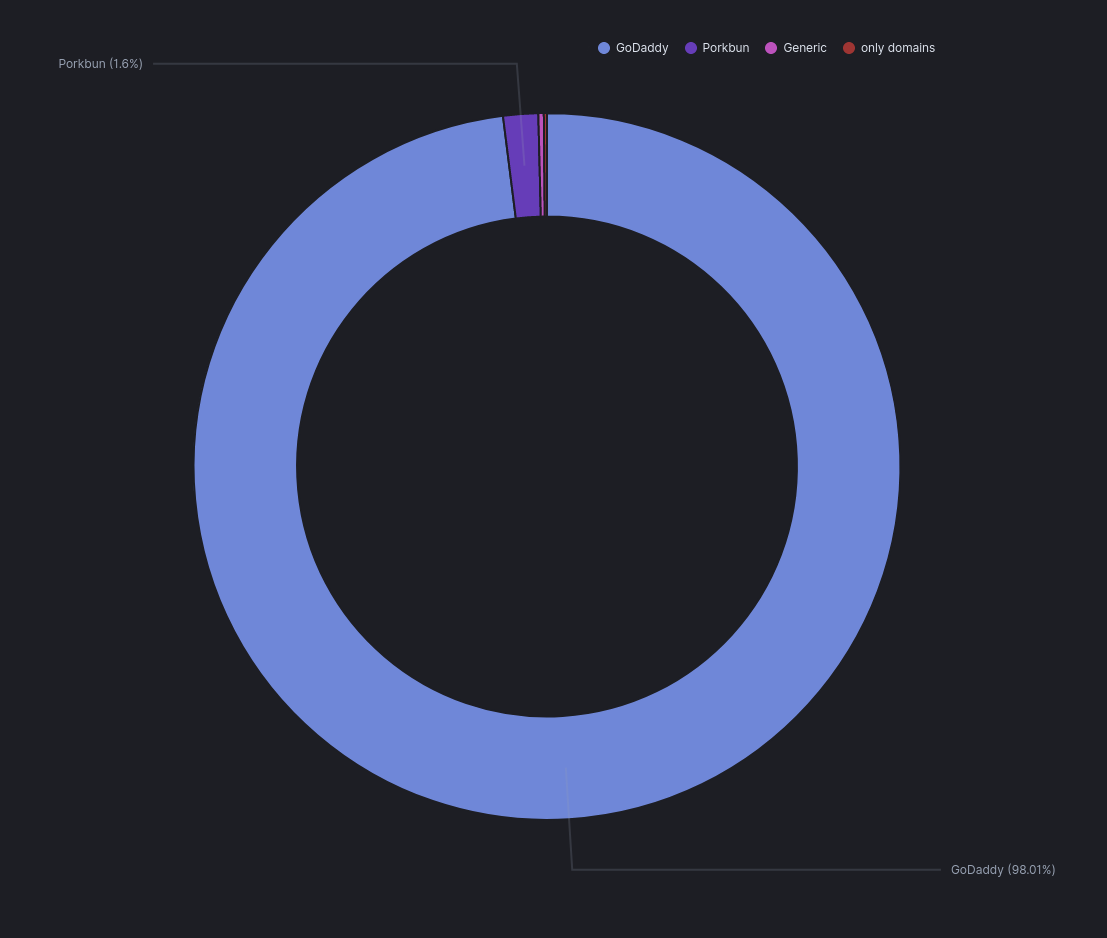
I exclusively focused on OCR extraction of English words from parked domain templates from GoDaddy, Porkbun, and OnlyDomains as I saw these templates the most frequently while browsing by hand. The breakdown below shows that of these three providers GoDaddy comes in at 98%. This breaks down to 2,759 domains in my dataset that are parked via GoDaddy templates.
The text extracted from other domains showed a handful of other registrar’s when searching for the word “parked” or “registered” included 831 hits. Finally, 3k domains contained a default server error of “internal error - server connection terminated”.
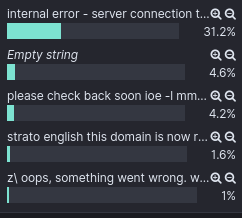
In total, this breaks down to 6,843 domains that were either parked or had server 500 errors when screenshots were being taken.
OCR worked well for some parked domain text, but floundered for others. This task was made trivial via some Python and the pytesseract library that performed the heavy lifting. This library uses Google’s Tesseract OCR engine for text extraction. It’s important to note that OCR is not a silver bullet for tasks like these and exception handling for image processing is a must.
DIY Kits, T-Shirts, Price Gouging and Scams
A significant number of “DIY” covid-19 test kits were being advertized within a dataset. These test kits largely varied in price and made several claims that at of this writing are unfounded by scientific reporting (ex: 15-minute tests) not to mention the accuracy of said tests.

In addition to the tests, several legitimate entrepreneurs are creating clever for t-shirts, coffee mugs, and hoodies to sell during these times.

E-commerce sites selling toiletries, hand sanitizers, and medical masks at drastically increased
prices were also discovered. This is practice is known as price gouging.
A specific e-commerce site within this data set was requesting USD $79.99 for
10 rolls of toilet paper.


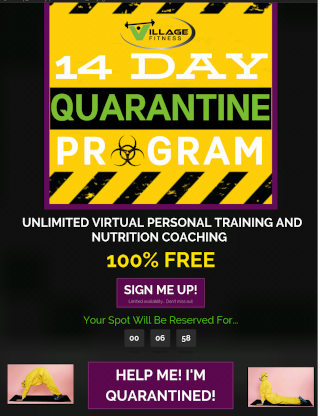
Finally, there was also a fair amount of individuals capitalizing on fitness programs targeted for the pandemic.
Phishing
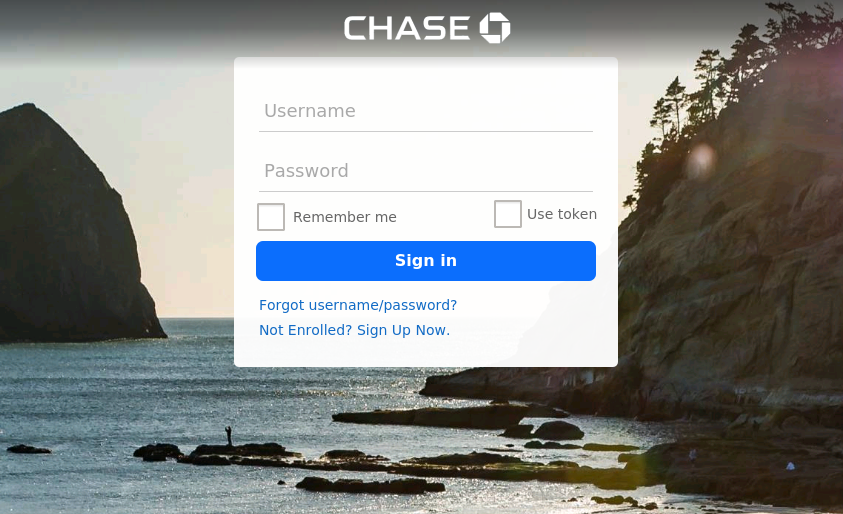
More traditional phishing attacks were seen in the form of modified login pages of popular web services. Some phishing sites relied on modifying the display page to have content related to the coronavirus. This can be seen in the fake Airbnb page below.

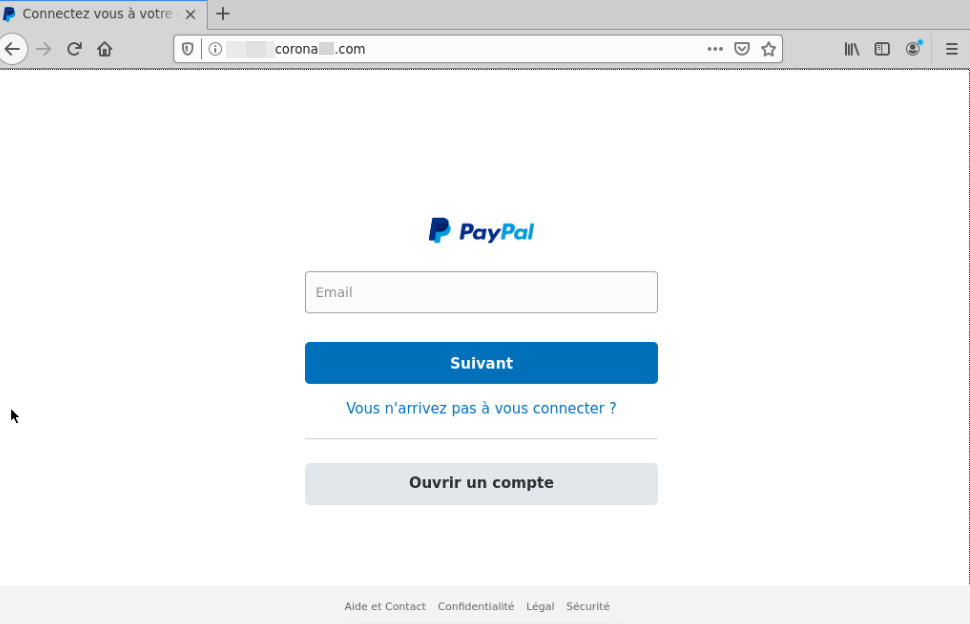
Others relied on believable domain names alone and looked to be apart of a
larger “spray-and-pray” style of phishing.
Several sites seemed to be in the middle of being set up or were misconfigured and
had directory indexing
enabled which resulted in directory listing being captured within the screenshot material.
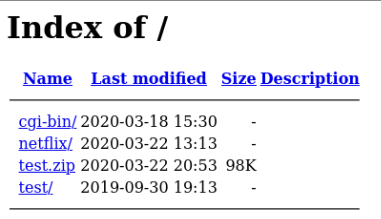
These misconfigurations revealed a phishing toolkit known as “16Shop”.
16Shop
Within the screenshot data, exposed directory listings contained several folders presumably staged to be used in phishing attacks. Revising these domains throughout the course of this project proved this to be correct as domains related to Paypal, Apple, and others were stood up. Potentially the most interesting discovery was what appeared to be a phsihing kit sold by 16Shop. These phishing kits are obtainable through various malware sample providers (ex: Virustotal, Malshare, etc…).
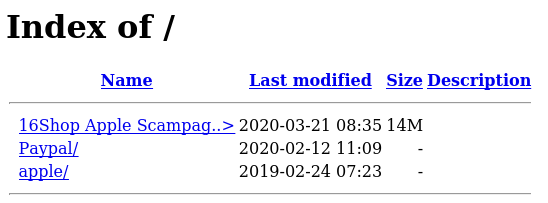
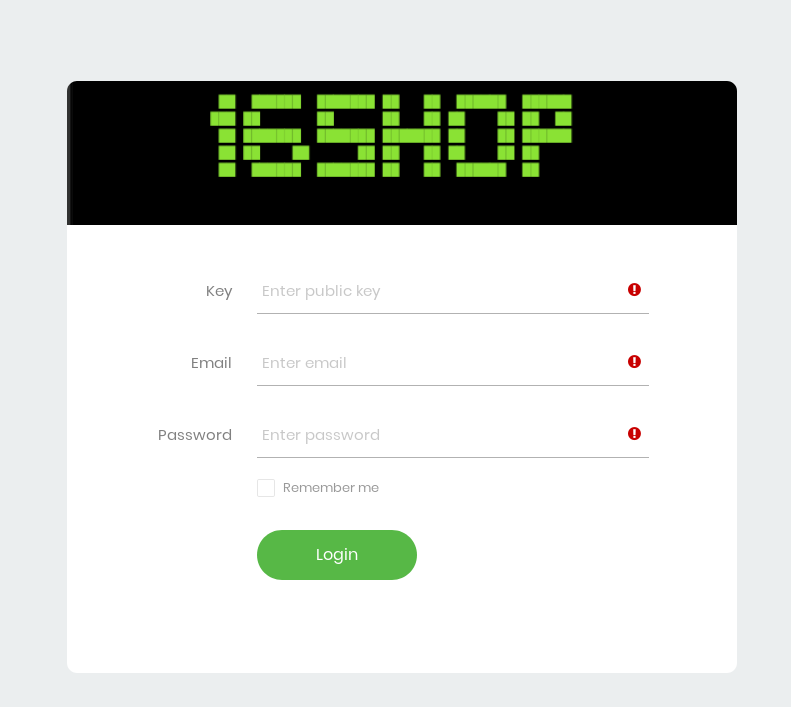
16Shop’s phishing kit is well documented and contains advanced phishing features such as additional end-used verification and anti-detection mechanisms. This includes linking to a 3rd party API for end-user verification as well a robust blacklist of IPs to block. For further information on this actor and the kit’s capabilities, I suggest looking at Zerofox and McAfee’s writeup.
Site defacements
Another interesting data point within the screenshot data was the site defacement occurring within a specific subset of domains. In order to not give publicity to the group I will refrain from uploading the data. However there were two distinct groups defacing webpages with their hacking groups moniker.
Beyond The Blog
Several companies are coming together during this time and providing resources and datasets to enable researchers and security practitioners to fight those taking advantage of the pandemic. I encourage all those interested to dive into the dataset released by DomainTools, and begin understanding the landscape surrounding Covid-19 phishing domains.